The Brier Patch
March 23, 2026
Predicting the future is hard. Unfortunately, so is checking whether or not your predictions were any good. Before we give LLMs jobs as fortune tellers, we ought to consider how forecasting skill is actually measured.
Proper Scoring
By far the most common scoring function is the Brier score, a fancy name for mean squared error (MSE). Suppose I predict an chance that you read this whole article. If you do, I receive a score of . If not, well, . Brier scoring is a strictly proper scoring rule, meaning that forecasters are incentivized to be honest:
There’s no way to reduce your expected score by misrepresenting your true belief. Readers of our previous blog post may recall that we used to quantify the value of information. KL divergence does satisfy the following:
In plain English, all this really means is that if the price of a prediction market already reflects your prior, you shouldn’t bother trading on it. We obviously can’t use KL divergence as a scoring function though, because while the outcome is observable, the ground truth probability isn’t.1 Note that another intuitive scoring function, the mean absolute error (MAE), is not proper:
Thus MAE incentivizes overconfidence. Does that make Brier score our best option? Maybe.2 But it has one obvious flaw: forecasting on high entropy events is penalized identically to making bad forecasts. Suppose I ask you to predict whether or not JD Vance will win the 2028 Presidential Election. Having little information, you put the odds at — the most entropic possible answer. You will receive a Brier score of regardless of what happens. This feels like a distinctly unimpressive forecast: you literally have no idea. On the other hand, suppose I asked you to forecast the outcome of a coin flip and you answered . Lo and behold you would again receive a score of even though you produced the best possible guess. But how can you prove it?
Can Chaos Be Well Calibrated?
Since the days of Aristotle, people without anything better to do have argued about determinism. After all, the physical world appears to behave deterministically until you zoom in far enough. As a society, we tend to selectively accept nondeterminism. We understand the aforementioned coin flip to be truly random, whereas we prefer to attribute our subjective uncertainty regarding the outcome of an election to our own ignorance. When the true outcome feels knowable, Brier score seems appropriate. When it doesn’t, we instead care about calibration. Consider all of the distinct events that you might assign a probability of occurring. If the fraction of those events that actually occur is close to , you’re well calibrated. The folks at calibration.city produced a wonderful visualization comparing calibration across major prediction platforms:
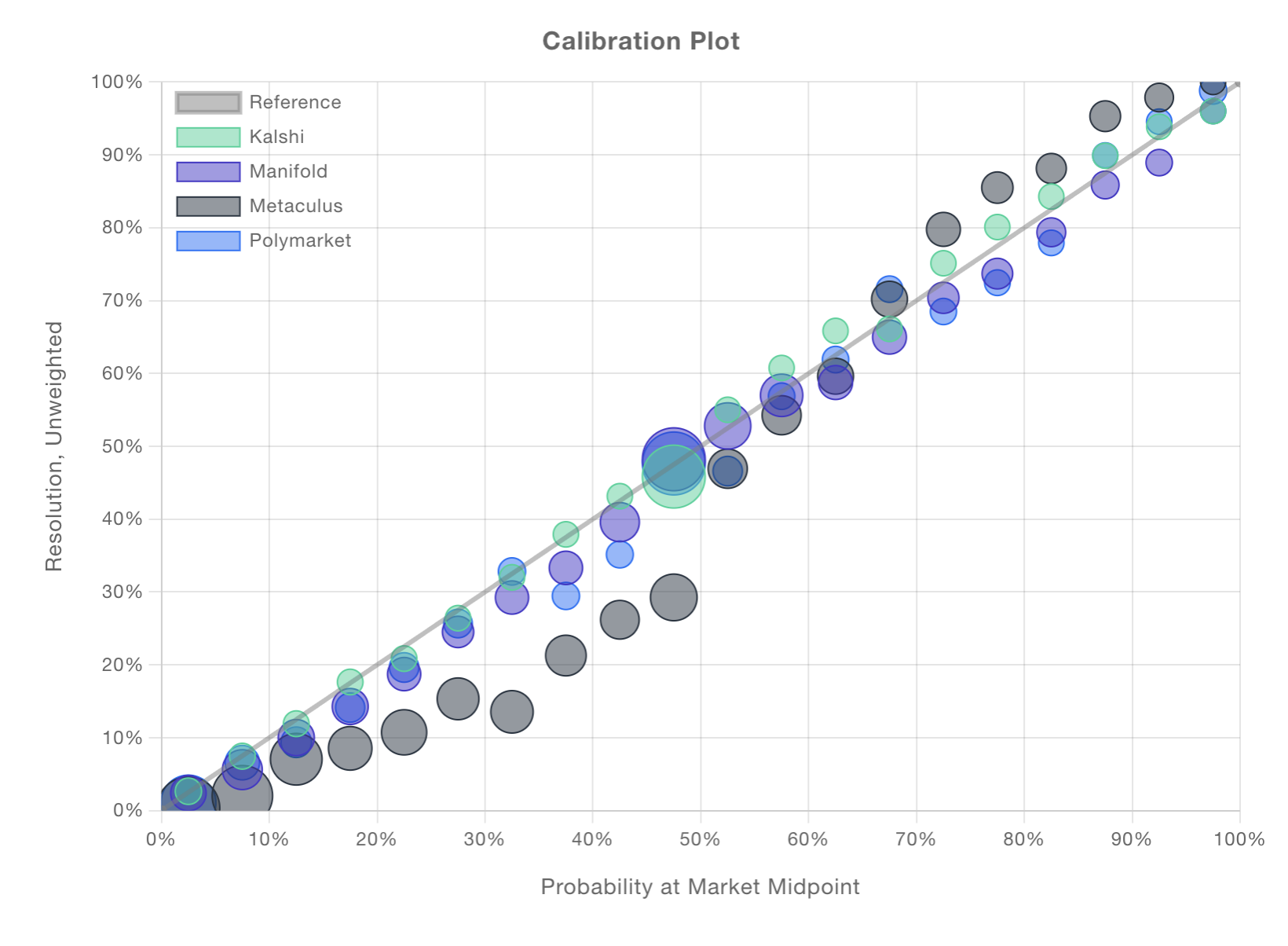
Calibration is something that good forecasters should have, liquid prediction markets behave like good forecasters, and they are well calibrated. Hooray! Unfortunately, being well calibrated is a necessary but not sufficient condition to demonstrate forecasting skill. Suppose I predicted the outcome of basketball games by selecting a team at random and estimating their probability of winning at . I’d be perfectly calibrated but completely useless.
First, Know Thyself
Suppose you’re a politician with two geopolitics advisors: Dave and Katie. You can and do ask Dave to predict just about everything, and he averages a Brier score of about . Impressive! Katie, on the other hand, can be a little coy. She rather understandably doesn’t like to make predictions on topics about which she knows little. Her predictions have yielded an impeccable Brier score of , but she has only answered two thirds of the questions that Dave has. Who would you rather keep on your staff? At the end of the day, it’s impossible to say with confidence which of the two is a better forecaster. I’d probably take Katie over Dave as a market maker, though. Sometimes knowing what you don’t know is all it takes.
1I apologize in advance to any adherents of determinism. Turn back now: it will only get worse.
2Best is a tricky thing to define, and while I will admit to believing that the drawbacks of Brier scoring are probably underdiscussed, the real answer is probably the complicated one: different types of forecasting need to be assessed differently.